Fork
Introduction au Parallélisme
------>> Serge « sans paille » Guelton Amer Baghdadi <<--------------------- --------------------->> Adrien Merlini Matthieu Arzel <<--------------------- ------------------>> Mathieu LEONARDON
Parallélisme de la Tarte au Pomme
[Q] Combien de temps pour faire une tarte aux pommes
pomme → eplucher → couper -+
pomme → eplucher → couper -+
+-→ garniture
pomme → eplucher → couper -+ |
pomme → eplucher → couper -+ |
+-→ cuire → miam
farine + |
+-→ mélanger -→ pâte -------+
beurre +
éplucher: 3min couper: 2min
cuire: 30min mélanger: 5minParallélisme de la Tarte au Pomme
[Q] À deux personnes ?
pomme → eplucher → couper -+
pomme → eplucher → couper -+
+-→ garniture
pomme → eplucher → couper -+ |
pomme → eplucher → couper -+ |
+-→ cuire → miam
farine + |
+-→ mélanger -→ pâte -------+
beurre +
éplucher: 3min couper: 2min
cuire: 30min mélanger: 5minParallélisme de la Tarte au Pomme
[Q] À quatre personnes ?
pomme → eplucher → couper -+
pomme → eplucher → couper -+
+-→ garniture
pomme → eplucher → couper -+ |
pomme → eplucher → couper -+ |
+-→ cuire → miam
farine + |
+-→ mélanger -→ pâte -------+
beurre +
éplucher: 3min couper: 2min
cuire: 30min mélanger: 5minAccélération théorique limitée - Loi d'Amdahl
- Même si 95% de la tâche peut être parallélisée, on ne peut pas dépasser x20 en accélération !
- Exemple : code qui prend 100 sec dont 95 sec parallélisable et 5 sec séquentiel
[Q] Limite d'accélération si 90% parallélisable ?
Exemples d'algorithmes parallèles
- Tri parallèle / parallel merge sort
- Map / reduce
- recherche d'un élément vérifiant une condition
Exemples d'architectures parallèles
> Hardware is like milk, you want it the freshest you can find.
- Ordinateur portable
- Serveur AWS
- …
Exemples d'abstraction pour le parallélisme
> Software is like wine, you want it with a bit of age.
- OpenMP
- pthread
- shell / xargs
Niveaux de parallélisme
> Michael Wolfe
- Node level → calcul sur grille en mémoire distribuée
- Socket level → plusieurs accélérateurs
- Core level → plusieurs processeurs en mémoire partagée
- Vector level → dans une unité attachée au processeur
- Pipeline level → utilisation du pipeline d’instruction
- Instruction level → VLIW et autres CISC
[Q] Et sur votre ordinateur portable ?
Pourquoi le parallélisme
- Loi de Moore → more transistors
- Loi d'Amdahl → $T(s) = (1 - p)T + pT÷s$
- diversité des architectures (#CPU, #unitévectorielles #GPU #FPGA #pipeline)
- ubiquité des multi-core ≠ langage avec un modèle séquentiel
Paléoinformatique
- CDC_6600: https://en.wikipedia.org/wiki/CDC_6600
- ILLIAC IV: https://en.wikipedia.org/wiki/ILLIAC_IV
- Cray 1: https://en.wikipedia.org/wiki/Cray-1
Performance(s) d'un programme
- Wall time : gettimeofday
- Accélération : $A = T_s ÷ T_p$
- Débit : e.g. Floating Point Operations per Second
- Sub-linéarité : $A < ||cpu||$
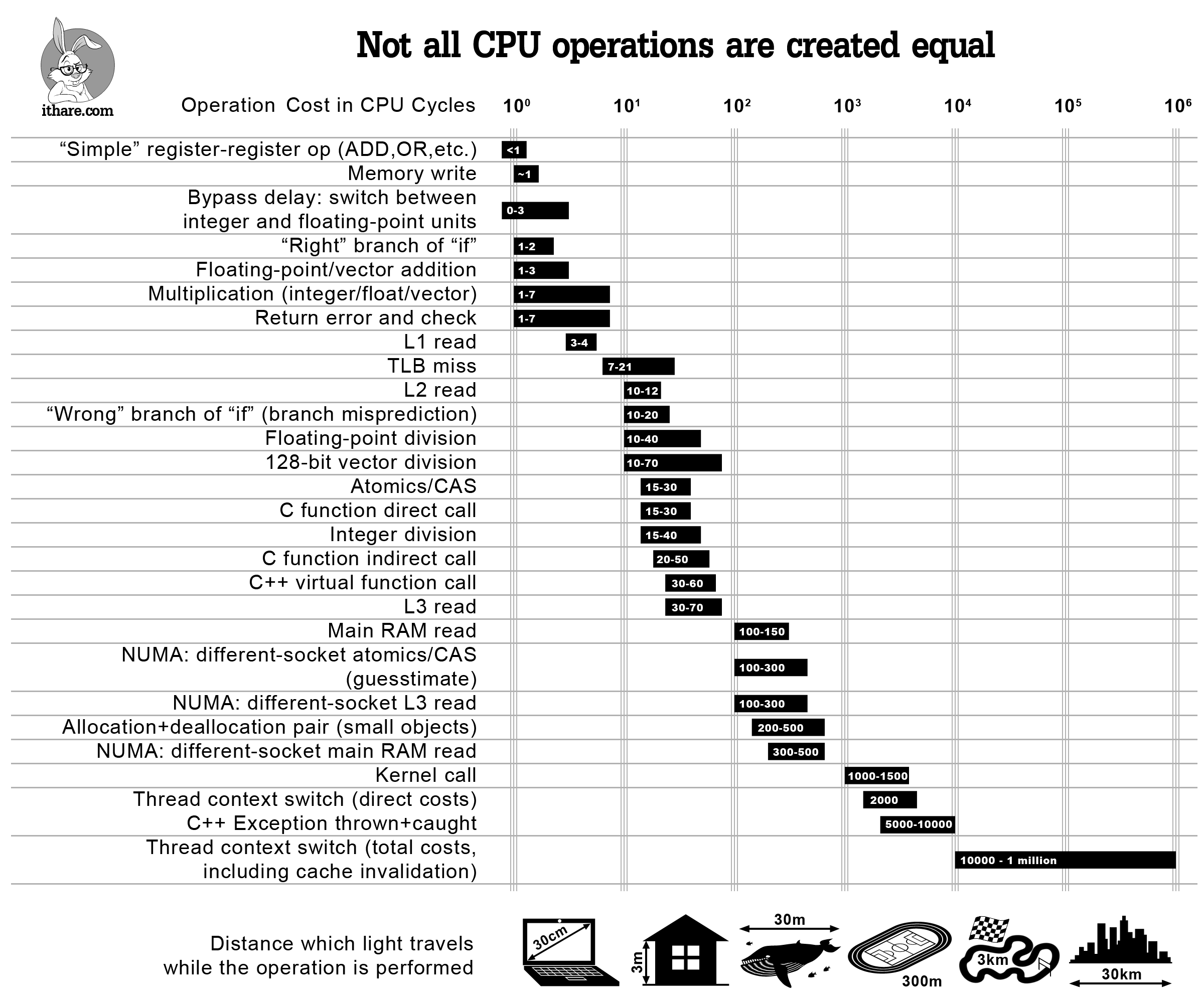
Parallélisme et consommation énergétique
> L'énergie est notre avenir, ́economisons-la
- Smartphone
- ARM in HPC
https://www.youtube.com/watch?v=nXaxk27zwlk / Tuning C++: Benchmarks, and CPUs, and Compilers! Oh My!
Parallélisme et mémoire
- memory wall
- localité, et cache-aware algorithm
- représentation des données
Notion de tâche
Tâche = calcul + données
- calcul = instruction, fonction, programme…
- données = en mémoire, sur disque
Avec un calcul sans effet de bord !
Un appel de tâche peut être bloquant ou non - bloquant
Notion de dépendance
Deux tâches sont interdépendantes si leurs exécutions ne peuvent pas être entrelacées.
Cela arrive si :
- elles produisent des données au même endroit
- l'une lit les données produites par l'autre
ce sont les conditions de Bernstein
Notion de graphe de tâche
Graphe = nœuds + arcs
- nœuds : les calculs
- arcs : les données produites / consommées
Un ordonnanceur va décider de l'exécution de ce graphe sur des ressources en respectant l'ordre topologique.
- notion de pipeline / latence
Taxonomy de Fynn
- Single Instruction Single Data: foo 1 ; bar 2
- Multiple Instr. Multiple Data: foo 1 & bar 2
- Single Instr. Multiple Data: xargs foo 1 2
- Multiple Instr. Single Data: foo 1 | bar
Modèles théoriques
- Parallel Random Access Machine : coût d'un accès mémoire = 0
- Modèle LogP: Latency Overhead Gap Processor
- Modèle bulk synchronous parallel: proc + comm + sync
Déroulement de l'UE
Plusieurs instances des mêmes concepts !
- Pragmatimse de l'ingénieur
- Node Level Parallelism
- Instruction Level Parallelism
- Data Level Parallelism
- Grpahical Processing Unit